
How I Reduced My CSS Bundle Size By More Than 20%
Ferenc Almasi •Have you ever peeked into the DOM of one of google’s pages, eg.: Gmail? If so, the very first thing you probably noticed is the fact that there are no readable class names, only random combinations of letters and numbers, just like in the hero image above. This can be useful for a couple of reasons:
- Reduces overall size
- Introduces scope isolation
- Obfuscates your code
How it’s Done?
Recently I had to update some content on my portfolio and I realized that there is no proper build system behind it. Most of the stuff required external 3rd party software, it required manual intervention to deploy my changes and the tech stack was outdated overall. So I decided to give it a fresh go, and while at it, why not make it more efficient as well?
Most of us are using Webpack these days and this can be done with the css-loader module, however since I’m using gulp in my setup, I’m going to focus on a different solution. There’s a great package called gulp-minify-cssnames, but there’s a catch. In order for it to work, you either have to use a prefix or a postfix to help the package find the relevant classes, which means, instead of writing .logo you would need to write .logo--s--. (--s-- can be anything else, it’s only purpose is to match the class in regex.) Since I did not want to use additional fixes for my class-names, I went with my own, simple solution.
There’s going to be a comparison at the bottom of this article if you’re only interested in that, for everyone else, here’s what I came up with:
const minifyClassNames = require('./tools/minifyClassNames.js');
gulp.task('minify-css-names', (done) => {
minifyClassNames([
{ input: 'src/index.html', output: 'build/index.html' },
{ input: 'src/assets/js/app.js', output: 'build/assets/js/app.js' },
{ input: 'src/assets/css/main.css', output: 'build/assets/css/main.css' }
]);
done();
});I created a task called minify-css-names and I also created a custom function called minifyClassNames which takes in an array of objects, containing an input and an output for the different files which need to be generated with the short CSS class-names. Input holds the current location I created a task called minify-css-names and I also created a custom function called minifyClassNameswhich takes in an array of objects, containing an input and an output for the different files that need to be generated with the short CSS class-names. Input holds the current location and the output is where it should be generated.
Note that you need to call done() after that to prevent gulp throwing errors.
Before diving into what the function actually does, let’s break down what steps we need to take in order to shorten our classes.
Breakdown
- Create the available class-names for use, eg.: “.a0, .b1”
- Collect all selectors from all CSS files
- Create a map containing the references between selectors and short names
- Apply the minified selectors to each input file and generate their output
Let’s start by outlining the function itself:
All we are going to have is an arrow function that takes in the files. I also pulled in the fs module as it’s easy to see from the breakdown that we will be reading and writing files.

Generating the short names
The next step is to actually generate the valid minified selectors for use.
const fs = require('fs');
module.exports = (files) => {
// The characters available to use for short class-names
const letters = 'abcdefghijklmnopqrstuvwxyz'.split('');
const numbers = '0123456789'.split('');
const identifiers = [];
const selectors = [];
// The map that will hold the reference between the short names and the original ones
const map = {};
// Create short class names, which results in 260 unique class-names
letters.forEach(letter => {
numbers.forEach(number => {
identifiers.push(`.${letter}${number}`)
});
});
};First, we define the characters from which we want to generate classes, in this case, we use the English alphabet and ten digits from 0 to 9 and split them into arrays so we can later loop over them. I also created two empty arrays, identifiers for holding the generated shortened names and selectors which will hold all the CSS selectors we have in our CSS files. Last but not least I also initialized a map object that will hold the reference between the original and the shortened class names. After that, we loop over each letter and number and add a combination of them to the identifiers array, starting from “.a0” all the way to “.z9”.
Collecting selectors
Next we want to read each CSS file we have passed into the function and collect the selectors from them. This can be done with a simple regex:
// Read each css file and build an array based on the selectors
files.forEach(file => {
if (file.input.split('.')[1] === 'css') {
const fileContent = fs.readFileSync(file.input, { encoding: 'utf8' });
/**
* Conditions:
* - Must start with either "." (classes) or "#" (ids)
* - Must continue with a letter
* - After one or multiple letters, optionally it can contain one or multiple letters again, numbers, dashes or underscores
* - Must be followed by two curly braces facing each other with any character in between them
* - Reference: https://stackoverflow.com/questions/12391760/regex-match-css-class-name-from-single-string-containing-multiple-classes
*/
const regex = /(\.|#)[a-z]+[a-z0-9-_]*(?![^\{]*\})/g;
// We create a unique array containing all the selectors only once
selectors.push(...new Set(fileContent.match(regex)));
}
});We first loop through each file and check if the extension equals to “css”. Then we read in the file with utf8 encoding. It’s important to specify it, otherwise we get a Buffer. Then we populate the selectors array with each match we get from the regex. This will gives us back an array with the selectors used in the CSS file. The only problem is that we probably use the same selectors multiple times, which results in duplicates. To get rid of duplicates, we can create a new Set from the array in combination with the spread operator to actually add strings to the selectors array, instead of Sets.
Generating the map
Now we have all the selectors we use throughout our project. For the next step we want to assign a short class name to each selector, eg.: match .root with .a0. This can be done in one line:
selectors.forEach((selector, index) => map[selector] = identifiers[index]);For each selector, we create a new node inside the map, with the selector’s name and give it a value from the identifiers array. This way we can ensure that each class name is only used once. After this, we should have a similar object ready:
{
".root": ".a0"
...
}So we can associate that our class .a0 corresponds with .root. We only have one thing left to do, the heart of the function; replacing each selectors with their corresponding short name in each input file and generate their output.
Generating the output
// Apply selectors to input files and generate the output
files.forEach(file => {
const containingFolder = file.output.split('/').slice(0, -1).join('/');
let fileContent = fs.readFileSync(file.input, { encoding: 'utf8' });
if (!fs.existsSync(containingFolder)) {
fs.mkdirSync(containingFolder, { recursive: true }); // recursive: true requires Node > 10.12.0
}
// Apply selectors to css
if (file.input.split('.')[1] === 'css') {
}
// Apply selectors to html
if (file.input.split('.')[1] === 'html') {
}
// Apply selectors to js
if (file.input.split('.')[1] === 'js') {
}
});Again, we start to loop over our input files. Since we can have deeply nested paths for the output, first we need to make sure that the folders we are about the generate the files into, already exists. On line 3, we get the name of the path without the filename itself. We split the output path by “/” and remove the last item. After that, we rejoin them by slashes. In case of dist/assets/js/app.js we get back dist/assets/js without app.js. Now we can use this variable to create folders recursively with the mkdirSync.
Note that you need to have at least v10.12.0 for Node in order to use the recursive flag.
Next we check for extensions and use different regexes based on them to create the output file. Let’s start with the first one:
// Apply selectors to css
if (file.input.split('.')[1] === 'css') {
Object.keys(map).forEach(key => {
/**
* Conditions:
* - Must start with either "." (classes) or "#" (ids)
* - Must be a whole word
* - Must not end by a dash or underscore
* - ps.: We also need to strip the key to get rid of the "." or "#" from the beginning
*/
fileContent = fileContent.replace(new RegExp(`(?:\\.|#)(?:^|\\b)${key.substring(1)}(?:$|\\b)(?![-_])`, 'g'), map[key]);
});
fs.writeFileSync(file.output, fileContent);
}We get the keys from our map and do a replace for each key inside it. All we need to do is replace each selector inside map with its value. The tricky part to get right is the regex. In this case, we check for words starting with “.” or “#” followed by a whole word that is also not followed by dashes or underscores. This way we can avoid it to match the word "project” for both .project and .project-image, which are two different classes. We also need to get rid of the very first character from the key which is either a dot or a hash, since the regex already accounts for that. And since we are using a variable as part of the regex, we need to use the new Regex constructor to actually build it. This is what we are going to replace with map[key] which holds the shortened class name. In case of the root example, this translates to the following:
fc.replace(/(?:\\.|#)(?:^|\\b)root(?:$|\\b)(?![-_])/g, '.a0');
After that, all we have to do is write the file to the output path we passed in. We do the exact same steps for HTML and JavaScript.
// Apply selectors to html
if (file.input.split('.')[1] === 'html') {
Object.keys(map).forEach(key => {
/**
* Conditions:
* - Must start with "class" or "id"
* - Optionally, followed by a valid class name
* - Not followed by dashes or underscores
* - Followed by a whole word (the class name itself)
* - Must not end by a dash or underscore
* - ps.: You need node version 9.x or above to use lookbehinds, else you need to use --harmony flag (https://node.green/)
*/
fileContent = fileContent.replace(new RegExp(`(?<=(?:class|id)="[a-z0-9-_\\s]*)(?<![-_])(?:^|\\b)${key.substring(1)}(?:$|\\b)(?![-_])`, 'g'), map[key].substring(1));
});
fs.writeFileSync(file.output, fileContent);
}Again, the tricky part is getting the regex right. In this example, we are using positive and negative look behind which are recently introduced in JavaScript, therefore you either need a node version higher than 9.x or you have to use the --harmony flag to make sure Node recognizes the pattern. This ensures that we only select words between either class or id attributes, but not from others or free-flow text. We can also have other classes preceding the actual class name we are looking for so we need to account for that with the following part: [a-z0–9-_\\s]*)(?<![-_]) and again, we check for dashes or underscores at the end since .project !== .project-image.
Probably the trickiest one to do is JavaScript files. You can have a lot of variations on how a selector is defined. Just think of jQuery vs vanilla, in jQuery you would write "#root" while in vanilla you simple do "root". Since I don’t use any frameworks or libraries for keeping things lightweight, I’m going to stick with vanilla.
// Apply selectors to js
if (file.input.split('.')[1] === 'js') {
Object.keys(map).forEach(key => {
/**
* Conditions:
* - Positive lookbehind, must start with "class" or "id"
* - Followed by a valid class name
* - Negative lookbehind, Not followed by dashes or underscores
* - Followed by a whole word (the class name itself)
* - Must not end by a dash or underscore
*/
fileContent = fileContent.replace(new RegExp(`(?<=('|")([a-z0-9-_\\s]*)?)(?<![-_])(?:^|\\b)${key.substr(1)}(?:$|\\b)(?![-_])`, 'g'), map[key].substring(1));
});
fs.writeFileSync(file.output, fileContent);
}In this example, the only difference between the HTML and the js regex, is that instead of checking for the keyword class or id at the beginning, we check if we are talking about a string at all? So we must start off with a quote whether it be single or double and the rest is essentially the same. After we feed the file through the regex, we write the output one last time. Combining everything together, this gives us the following function:
const fs = require('fs');
module.exports = (files) => {
// The characters available to use for short class-names
const letters = 'abcdefghijklmnopqrstuvwxyz'.split('');
const numbers = '0123456789'.split('');
const identifiers = [];
const selectors = [];
// The map that will hold the reference between the short names and the original ones
const map = {};
// Create short class names, which results in 260 unique class-names
letters.forEach(letter => {
numbers.forEach(number => {
identifiers.push(`.${letter}${number}`)
});
});
// Read each css file and build an array based on the selectors
files.forEach(file => {
if (file.input.split('.')[1] === 'css') {
const fileContent = fs.readFileSync(file.input, { encoding: 'utf8' });
/**
* Conditions:
* - Must start with either "." (classes) or "#" (ids)
* - Must continue with a letter
* - After one or multiple letters, optionally it can contain one or multiple letters again, numbers, dashes and underscores
* - Must be followed by two curly braces facing each other with any character in between them
* - Reference: https://stackoverflow.com/questions/12391760/regex-match-css-class-name-from-single-string-containing-multiple-classes
*/
const regex = /(\.|#)[_a-z]+[a-z0-9-_]*(?![^\{]*\})/g;
// We create a unique array containing all the selectors only once
selectors.push(...new Set(fileContent.match(regex)));
}
});
// Create a map containing the references between the original and the shortened class-names
selectors.forEach((selector, index) => map[selector] = identifiers[index]);
// Apply selectors to input files and generate the output
files.forEach(file => {
const containingFolder = file.output.split('/').slice(0, -1).join('/');
let fileContent = fs.readFileSync(file.input, { encoding: 'utf8' });
if (!fs.existsSync(containingFolder)) {
fs.mkdirSync(containingFolder, { recursive: true }); // recursive: true requires Node > 10.12.0
}
// Apply selectors to css
if (file.input.split('.')[1] === 'css') {
Object.keys(map).forEach(key => {
/**
* Conditions:
* - Must start with either "." (classes) or "#" (ids)
* - Must be a whole word
* - Must not end by a dash or underscore
* - ps.: We also need to strip the key to get rid of the "." or "#" from the beginning
*/
fileContent = fileContent.replace(new RegExp(`(?:\\.|#)(?:^|\\b)${key.substring(1)}(?:$|\\b)(?![-_])`, 'g'), map[key]);
});
fs.writeFileSync(file.output, fileContent);
}
// Apply selectors to html
if (file.input.split('.')[1] === 'html') {
Object.keys(map).forEach(key => {
/**
* Conditions:
* - Positive lookbehind, must start with "class" or "id"
* - Followed by a valid class name
* - Negative lookbehind, Not followed by dashes or underscores
* - Followed by a whole word (the class name itself)
* - Must not end by a dash or underscore
* - ps.: You need node version 9.x or above to use lookbehinds, else you need to use --harmony flag (https://node.green/)
*/
fileContent = fileContent.replace(new RegExp(`(?<=(?:class|id)="[a-z0-9-_\\s]*)(?<![-_])(?:^|\\b)${key.substring(1)}(?:$|\\b)(?![-_])`, 'g'), map[key].substring(1));
});
fs.writeFileSync(file.output, fileContent);
}
// Apply selectors to js
if (file.input.split('.')[1] === 'js') {
Object.keys(map).forEach(key => {
/**
* Conditions:
* - Positive lookbehind, must start with "class" or "id"
* - Followed by a valid class name
* - Negative lookbehind, Not followed by dashes or underscores
* - Followed by a whole word (the class name itself)
* - Must not end by a dash or underscore
*/
fileContent = fileContent.replace(new RegExp(`(?<=('|")([a-z0-9-_\\s]*)?)(?<![-_])(?:^|\\b)${key.substr(1)}(?:$|\\b)(?![-_])`, 'g'), map[key].substring(1));
});
fs.writeFileSync(file.output, fileContent);
}
});
};Caveats
This is a simplified representation of how one can generate short classes on their own without pulling in any additional modules or packages. This is nowhere near perfect nor it comes close to the complexity of similar official packages, therefore we have to note that this solution is not bulletproof. However, it’s an interesting case study and a working solution for such smaller projects as my portfolio. Let’s go over the implementation and note what are the pitfalls and what can be improved.
First, we start off by generating the unique identifiers. As it has been noted by the code example, this generates exactly 260 unique class-names, from “.a0” to “.z9”. In my case, this is more than enough since I’m only using 51 different selectors throughout my CSS files. In case of larger projects, this is nowhere near the required amount of unique selectors. Say you even have an external CSS library pulled into your project, taking Bootstrap as an example, v4.3.1 has more than 1500 selectors alone. At this scale, you need to start combining multiple letters and numbers together to get a wider range. (eg.: “.ab0” or “.bc91”)
Next, we have the regex for getting the selectors from the CSS files. It’s fairly robust, but in this case it is conditioned for a set of coding styles. For example, your project might include class names that start with an underscore or uppercase letters, eg.: ._root or .Root. This only covers the cases where a class name is formatted according to the conditions specified in the code example. On the upside, this forces you to follow conventions that makes your code consistent, on the downside, this can introduce bugs if there’s no linter in place to catch invalid class names or you are not familiar with the inner workings of your project.
I would also like to point out the different regexes used for the different file extensions. To give you an example, imagine you have a class name called .number. What happens if you have a type check in your js file checking if typeof variable === 'number'? You guessed it, that would match for the string number without a doubt causing you a bug.
These are all examples that need to be taken into consideration when using a solution similar to this, so be cautious. If you can, use an official package for the job that is covered for most cases like Webpack’s css-loader and only go with this solution when you either have no other option for your setup or you want to have full control over every aspect of your code. Nevertheless, let’s finally look at what this means in terms of performance.
Comparison
- Before: 8.6 KB (after minification)
- After: 6.64 KB (after minification)
This is a 22.8% decrease in size, which could be even doubled if we were to have a bigger bundle size. The bigger the size, the more impact it makes. This is also even further reduced once it’s deployed into the server which serves it with gzip compression, resulting in 2.8 KB only.
In terms of performance, this resulted in an average of 0.775s gain for the metrics below.
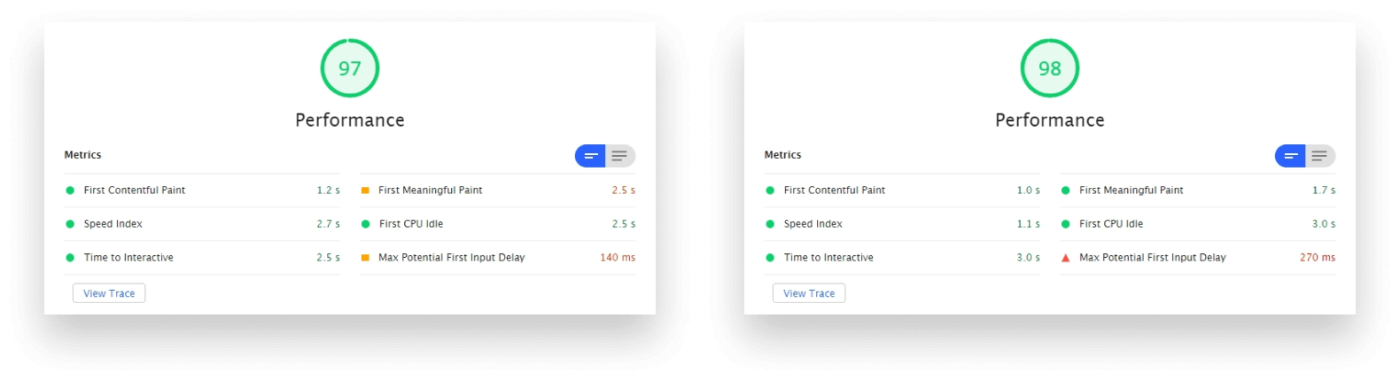
Audits were made on Desktop, with a throttling of Simulated Slow 4G with 4x CPU Slowdown
Summary
It’s a great way to get some performance out of your site, especially since it does not only reduce your CSS bundle but your HTML and JavaScript files as well. Since it needs to rewrite the references for the post-build class-names and the three together add up. They say every little count but this can really make a difference and impact your performance. 👌

Rocket Launch Your Career
Speed up your learning progress with our mentorship program. Join as a mentee to unlock the full potential of Webtips and get a personalized learning experience by experts to master the following frontend technologies:
Courses

CSS - The Complete Guide (including Flexbox, Grid and Sass)

The HTML & CSS Bootcamp

The Creative HTML5 & CSS3 Course
Recommended
Why Do We Need to Care About Accessibility?
